test data machine learning|training data vs test validation : white label Omissions in the training of algorithms are a major cause of erroneous outputs. Types of such omissions include:• Particular . See more Resultado da 02/12/2023 15:00. Palpites Futebol Americano Palpites NFL. Mike Evans em partida pelo Tampa Bay Buccaneers no dia 05.11.2023 (© IMAGO / ZUMA Wire) Conteúdo. Às 18h05 (horário de Brasília) no Raymond James Stadium, teremos um dos dois jogos entre times da mesma divisão da Semana 13: .
{plog:ftitle_list}
Resultado da 15K Followers, 157 Following, 15 Posts - See Instagram photos and videos from Regina 曆懶 (@priv_rereschneider)
A test data set is a data set that is independent of the training data set, but that follows the same probability distribution as the training data set. If a model fit to the training data set also fits the test data set well, minimal overfitting has taken place (see figure below). A better fitting of the training data set as . See moreIn machine learning, a common task is the study and construction of algorithms that can learn from and make predictions on data. Such algorithms function by making data-driven predictions or decisions, through building a See moreA validation data set is a data set of examples used to tune the hyperparameters (i.e. the architecture) of a classifier. It is sometimes also called the development set or . See moreTesting is trying something to find out about it ("To put to the proof; to prove the truth, genuineness, or quality of by experiment" . See more
what is dataset differentiate between training and testing
training dataset in machine learning
Omissions in the training of algorithms are a major cause of erroneous outputs. Types of such omissions include:• Particular . See moreA training data set is a data set of examples used during the learning process and is used to fit the parameters (e.g., weights) of, for example, a classifier.For classification tasks, a supervised learning algorithm . See moreIn order to get more stable results and use all valuable data for training, a data set can be repeatedly split into several training and a validation data sets. This is known as See more
• Statistical classification• List of datasets for machine learning research• Hierarchical classification See more
Test Data. Test data is the subset of the dataset used to provide an unbiased evaluation of a final model fit on the training dataset. It is only used after the model has been trained (and. There is much confusion in applied machine learning about what a validation dataset is exactly and how it differs from a test dataset. In this . Training data teaches a machine learning model how to behave, whereas testing data assesses how well the model has learned. Training Data: The machine learning model is .
what are the best practices to test ssis package
training data vs testing ai

well test package for sale
Learn how to divide a machine learning dataset into training, validation, and test sets to test the correctness of a model's predictions.The train-test split technique is a way of evaluating the performance of machine learning models. Whenever you build machine learning models, you will be training the model on a specific dataset (X and y). Test Dataset: The sample of data used to provide an unbiased evaluation of a final model fit on the training dataset. The Test dataset provides the gold standard used to evaluate the model. It is only used once a model is .September 13, 2021. Here's the first rule of machine learning — Don't use the same dataset for model training and model evaluation. If you want to build a reliable machine learning model, you need to split your dataset into the .
Welcome to our deep dive into one of the foundations of machine learning: Training, Validation, and Test Sets. In this blog post, I’ll explain the purpose of having these different machine learning datasets, explaining their .
In most supervised machine learning tasks, best practice recommends to split your data into three independent sets: a training set, a testing set, and a validation set. To learn why, let's pretend . When developing a machine learning model, one of the fundamental steps is to split your data into different subsets. These subsets are typically referred to as train, test, and validation data. Machine learning algorithms learn from data. It is critical that you feed them the right data for the problem you want to solve. Even if you have good data, you need to make sure that it is in a useful scale, format and even that .
Training data and test data sets are two different but important parts in machine learning. While training data is necessary to teach an ML algorithm, testing data, as the name suggests, helps you to validate the . The cause of poor performance in machine learning is either overfitting or underfitting the data. In this post, you will discover the concept of generalization in machine learning and the problems of overfitting and underfitting that go along with it. Let’s get started. Approximate a Target Function in Machine Learning Supervised machine learning is best . In Machine Learning, a Test Dataset plays a crucial role in evaluating the performance of your trained model. In this blog, we will delve into the intricacies of test dataset in machine learning, its significance, and its indispensable role in the data science lifecycle.. What is Test Dataset in Machine Learning? A test dataset is a collection of data points that the .
training data vs test validation
Train, Test, and Validation Sets By Jared Wilber. In most supervised machine learning tasks, best practice recommends to split your data into three independent sets: a training set, a testing set, and a validation set. To demo the reasons for splitting data in this manner, we will pretend that we have a dataset made of pets of the following two types:
What is Testing Data? Once your machine learning model is built (with your training data), you need unseen data to test your model. This data is called testing data, and you can use it to evaluate the performance and progress of your algorithms’ training and adjust or optimize it for improved results. Testing data has two main criteria. It .
In Machine Learning we create models to predict the outcome of certain events, like in the previous chapter where we predicted the CO2 emission of a car when we knew the weight and engine size. . It is called Train/Test because you split the data set into two sets: a training set and a testing set. 80% for training, and 20% for testing. You .
Once you choose and fit a final machine learning model in scikit-learn, you can use it to make predictions on new data instances. . 1.a But, the challenge is that I am trying to see the predictions for every piece of test data with its video label being used in the operations. The amount of files for testing is 16 according to the split . Read on to understand the difference between training data vs. test data in machine learning. Knowing the difference and ensuring you’re using both the right way is essential. In this article, we will discuss training data vs. test data and explain more about each. The train-test split procedure is used to estimate the performance of machine learning algorithms when they are used to make predictions on data not used to train the model. It is a fast and easy procedure to perform, the results of which allow you to compare the performance of machine learning algorithms for your predictive modeling problem.
The key to getting good at applied machine learning is practicing on lots of different datasets. This is because each problem is different, requiring subtly different data preparation and modeling methods. In this post, you will discover 10 top standard machine learning datasets that you can use for practice. Let’s dive in. Update Mar/2018: Added [.]The training data varies depending on whether we are using Supervised Learning or Unsupervised Learning Algorithms. For Unsupervised learning, the training data contains unlabeled data points, i.e., inputs are not tagged with the corresponding outputs.Models are required to find the patterns from the given training datasets in order to make predictions.
When modeling, it is important to clean the data sample to ensure that the observations best represent the problem. Sometimes a dataset can contain extreme values that are outside the range of what is expected and unlike the other data. These are called outliers and often machine learning modeling and model skill in general can be improved by .
well test package
Test Dataset: The sample of data used to provide an unbiased evaluation of a final model fit on the training dataset. . All in all, like many other things in machine learning, the train-test-validation split ratio is also quite . In the current age of the Fourth Industrial Revolution (4IR or Industry 4.0), the digital world has a wealth of data, such as Internet of Things (IoT) data, cybersecurity data, mobile data, business data, social media data, health data, etc. To intelligently analyze these data and develop the corresponding smart and automated applications, the knowledge of .
On the contrary of that if the p-value is less than 0.05 in a machine learning model against an independent variable, then the variable is considered which means there is heterogeneous behavior with the target which is useful and can be learned by the machine learning algorithms. The steps involved in the hypothesis testing are as follow:
Overfitting is a common explanation for the poor performance of a predictive model. An analysis of learning dynamics can help to identify whether a model has overfit the training dataset and may suggest an alternate configuration to use that could result in better predictive performance. Performing an analysis of learning dynamics is straightforward for .Cross-validation is a resampling procedure used to evaluate machine learning models on a limited data sample. If you have a machine learning model and some data, you want to tell if your model can fit. You can split your data into training and test set. Train your model with the training set and evaluate the result with test set. Machine Learning uses a data-driven approach, It is typically trained on historical data and then used to make predictions on new data. . and to test the model on new data. The saving of data is called Serialization, while restoring the data is called Deserialization. Also, we deal with different typ
Data is a crucial component in the field of Machine Learning. It refers to the set of observations or measurements that can be used to train a machine-learning model. The quality and quantity of data available for training and testing play a significant role in determining the performance of a machine-learning model.10,828 machine learning datasets . The training data is split into 3 partitions of 100hr, 360hr, and 500hr sets while the dev and test data are split into the ’clean’ and ’other’ categories, respectively, depending upon how well or challenging Automatic Speech Recognition systems would perform against. Each of the dev and test sets is . Data preparation. A few hours of measurements later, we have gathered our training data. Now it’s time for the next step of machine learning: Data preparation, where we load our data into a suitable place and prepare it for use in our machine learning training. We’ll first put all our data together, and then randomize the ordering.
What is Train and Test Data in Machine Learning? Train and test data are two parts of the same dataset used in machine learning. The training data is used to teach the model, while the test data is used to see how well the model learned. Think of it like studying for a test. You use your textbook to learn.Now that we have a foundation for testing traditional software, let's dive into testing our data and models in the context of machine learning systems. 🔢 Data. So far, we've used unit and integration tests to test the functions that interact with our data but we haven't tested the validity of the data itself.Since 2018, millions of people worldwide have relied on Machine Learning Crash Course to learn how machine learning works, and how machine learning can work for them. We're delighted to announce the launch of a refreshed version of MLCC that covers recent advances in AI, with an increased focus on interactive learning.
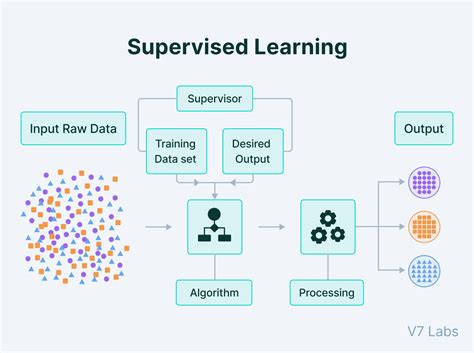
So what is the test set in machine learning? A training set is a subset of data used to train a model; Test set—a subset used to put the trained model to the test; Your goal is to develop a model that generalizes well to new data, assuming your test set fits the two constraints mentioned above. Our test set acts as a stand-in for new information.
Últimos Resultados|M1lhão - Jogos Santa Casa - Últimos Re.
test data machine learning|training data vs test validation